
| To jump to a topic, click your choice below: | ||||
|---|---|---|---|---|
| Protocol Submission | AI FDA FAQs | Glossary of Risk | AI Video Series | Additional Resources |
| To jump to a topic, click your choice below: | ||||
|---|---|---|---|---|
| Protocol Submission | AI FDA FAQs | Glossary of Risk | AI Video Series | Additional Resources |
The AI Protocol Submission Guidance for Researchers offers guidance to researchers conducting research that uses or develops Artificial Intelligence (AI). In this guidance, “AI system” refers broadly to any AI-based tool, model, or software used or developed as part of a human research study.
Not all sections will apply to every study. Researchers should use their judgment to determine which areas require AI-related explanation and what level of detail is appropriate. For example: A study using an AI transcription service to transcribe recorded interviews may only need to include the AI system name. Then, confirm whether the third-party vendor has access and maintains ownership of the data being transcribed and include this information in the informed consent.
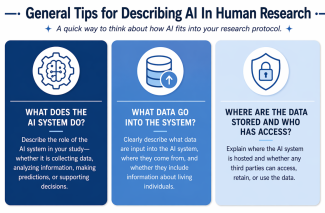
In the Study Design section of a protocol application, researchers are asked to describe and explain the overall study design. If using or developing AI, researchers should describe how the AI system fits within the study design. This information helps IRB reviewers determine whether the technology introduces additional risks or may require additional regulatory review or oversight.
Use the following guidance to clearly describe the AI system and how it functions within the study design:
GENERAL INFORMATION
AI System Name and Version: Including the system name and version helps clearly document what system was used, which supports transparency, reproducibility, and review of the research. (e.g., “GPT-4.1,” “custom convolutional neural network v2.3”)
Whether the AI System is Being Used or Developed: Your description should reflect whether you are using an existing AI system or developing one as part of the research.
In general, studies using an existing system should focus on how the system is applied, while studies modifying the use of AI or developing AI should also describe how the system is built, trained, or updated.
For AI development, indicate what development stage the AI system is in (e.g. record review for data testing and training).

What the AI System Does or What the AI System Will Do: Describe the AI system’s function in plain language:
WHEN ADDITIONAL DISCLOSURE IS IMPORTANT
The following situations do not necessarily require additional detail, but they should be clearly disclosed in the protocol, as they may raise important ethical, regulatory, or oversight considerations.
General Use:
Non-Standard or Higher Risk Use:
Developing or Integrating AI Systems in Clinical Care:
COMMON PITFALLS
AI Data Description: In the Data Collection section of a protocol application, researchers are asked to describe what data are collected and why. Here, researchers should focus on describing what collected data will go into the AI system. Because AI systems depend on data to function, the type and source of these data are key to understanding potential risks related to privacy, confidentiality, consent, and group harms.
Use the following guidance to clearly describe what data the AI system will access:
GENERAL INFORMATION
An AI data description should indicate whether:
Collecting Data from Living Individuals: (e.g., through surveys, chatbots, wearable devices)
De-identified Secondary Data: (e.g., commercial, licensed, or publicly available datasets used as input to the AI system)
Electronic Health Records or Imaging Data: Specify whether data are retrospective or prospective, and how they are accessed or integrated into the AI system.
Student Records: (e.g., educational data protected under FERPA or institutional policies)
Combining Data with Other Datasets or Auxiliary Information: (e.g., linking datasets, enriching with external sources, or merging across systems)
Known limitations or biases in the dataset(s): See AI Glossary of Risks
COMMON PITFALLS
In the Records, Privacy, and Confidentiality section of a protocol application, researchers are asked to describe how data are stored and who has access. Because AI systems may process data in external or cloud-based environments, understanding how data move through and are controlled within these systems is essential for assessing risks to privacy, confidentiality, and unauthorized access.
Use the following guidance to clearly describe where the AI system is hosted and who may access, retain, or use the data:
GENERAL INFORMATION
Compliance with Institutional and Regulatory Requirements: Per AR 10.7, Protected Health Information (PHI) or Personally Identifiable Information (PII) should not be entered into a generative AI tool or other software unless the UK HealthCare InfoSec Data Sharing Committee has confirmed the tool is HIPAA-compliant and supports PHI
Where the AI system is Hosted: Clearly indicate whether the AI system is:
If using a cloud-based or third-party system, describe whether data entered in the system may be stored, accessed, or used by the vendor (e.g., for service improvement or system training).
When AI systems are used within a UK-protected environment (e.g., UK Centered for Applied AI), both the system and the data remain under institutional control. A helpful way to think about this is with a Hotel California analogy. The AI system can “check in” to analyze the data, but it cannot leave the environment with the data.

Data Access and Ownership: Indicate whether the AI vendor has access to the data and whether the vendor retains any ownership, usage rights, or licensing permissions over the data.
UK ITS/GRC: Indicate whether a data privacy review was conducted by UK Information Technology Services (ITS) Governance, Risk and Compliance (GRC) team.
Additional Data Security and Privacy Controls: Describe safeguards in place to mitigate AI-related risks (e.g., access controls, encryption, data minimization, monitoring)
Consult the FDA Digital Center for Excellence and use the Digital Health Policy Navigator to determine if subject to FDA oversight and applicable FDA legal and regulatory requirements.
Consult the FDA website and Graphic, Final FDA Guidance, and/or consult the Digital Center for Excellence with questions.
For formal classification of a product, a 513(g) request for information to the applicable Office of Health Technology (OHT). You may also engage the FDA or request feedback through the Pre-Submission program.
Use the Federal Trade Commission (FTC) Mobile Health App Interactive Tool for determining which laws and rules may apply.
| TERM | DEFINITION |
|---|---|
| Anthropomorphism | Also known as over-personification, anthropomorphism ascribes human features/characteristics to the model. This can lead to overconfidence in the model's performance and lax human oversight. |
| Bias | AI bias occurs when data output perpetuates existing prejudices. Bias can be imbedded in discriminatory data training sets, or it can be introduced through subjective algorithm development. |
| Data Drift | Data drift is a reaction to statistical and characteristic changes in input data that the model is not trained to handle. The model cannot generalize beyond the training data. This can lead to off-purpose data output and performance decline. |
| Data Fusion | Data fusion is the process of combining multiple data sources. The sources generally include raw data and produce false positives that can lead to inaccurate data profiles. Raw data is unlabeled data that has not been cleaned, organized, or summarized. Data fusion can also lead to re-identification. |
| Data Leaks | Data leaks refer to intended and unintended exposure of sensitive, private, or proprietary data. Data leakage commonly refers to vendor access and ownership of protected data as a stipulation for use of the third party’s AI model. Leaks can occur at any point in AI use or development. |
| Data Minimization | Data minimization is the process of identifying and inputting the least amount of data points to fulfill the model's purpose. The intention is privacy protection. However, it can also lead to a loss of data that may limit results and impact accuracy. Another concern would be the potential for unintentionally including bias (e.g., excluding race, gender, or age data points). |
| Deepfakes | A deepfake is audiovisual content intentionally altered to disseminate false information. Deepfakes can contaminate results when inputting unsupervised data from open AI sources. Contaminated results could potentially infiltrate supervised databases and/or peer reviewed publications. This could lead to perpetuating the falsehood and raise intellectual property concerns. |
| False Negative | A false negative is a data output prediction/decision that incorrectly indicates an attribute/condition is not present when it is present. False negatives can lead to missed opportunities to participate in research in a pre-clinical effort to locate a target population. False negatives can also lead to a misdiagnosis in a clinical trial. |
| False Positive | A false positive is a data output prediction/decision that incorrectly indicates an attribute/condition is present when it is not present. A high rate of false positives generally indicates biased training data. False positives can lead to carrying forward misguided prejudice as a result. |
| Hallucinations | A hallucination is nonsensical and inaccurate data output from a Large Language Model (LLM). Underlying causes for hallucinating LLM responses include the lack of real-world context and insufficient or poor-quality data. Vague prompting combined with an expectation to “guess” can also produce hallucinations. |
| Interpretability | Interpretability describes how a model makes a prediction or decision. In a model that combines different types of data, interpretability also includes how different data types interact. |
| Misclassification | AI data classification is the process of sorting and labeling data inputted into AI models. Misclassification occurs when the AI model incorrectly sorts and/or labels data output. |
| Overfitting | Overfitting is when a model performs poorly on new data because it memorized the training data. It occurs for a variety of reasons (e.g., insufficient training data, training too long on the same data, too much emphasis on noise in the data that is real-world uncommon). |
| Over-optimization | Optimization is the process of adjusting the mathematical parameters of an algorithm to improve accuracy and reduce errors. Over-optimization occurs when an algorithm metric is too narrowly defined on a specific task. A hyper-tuned algorithm can develop blind spots that lead to misidentification or misunderstanding in a prediction or decision. |
| Over-reliance | Over-reliance involves placing too much trust in the output of a model. This can cause performance errors, and that might otherwise be identified through more diligent human scrutiny. |
| Poisoned Data | Poisoned data is incorrect, biased, or mislabeled data that can contaminate training sets. Data pulled from the internet, third-party platforms, and government can advance toxicity in the early stages of model development. |
| Re-identification | Re-identification is a process that results in linking a de-identified data source back to the identity of the de-identified individual. It generally occurs when data sets are combined, allowing an AI model to match data points in de-identified data and other publicly available data. |
| Skewed Data | Models trained on skewed data generate unequal predictions and decisions. Skewed data can produce higher/lower rate patterns of inconsistencies for a specific demographic population without justification. This can amplify already existing biases. |
| Synthetic Data | Synthetic data is trained on real-world data for the purpose of generating statistically identical data. This can lead to the re-identification of the de-identified real-world data. It can also generate an inaccurate representation of the real world and reinforce demographic inequities. |
The AI Adventures in Human Subjects Research Video Series offers researchers responsible-use strategies for mitigating the risk of employing AI in human subjects research.

Episode 1 provides the purpose for creating the video series, presents the beneficence conundrum, and introduces the data ancestors. [7:10]

Episode 2 offers strategies for mitigating the risk of inputting potentially biased historical data sets into AI models. [4:54]

Episode 3 offers strategies for mitigating the risk of combining de-identified data with publicly available auxiliary information. [4:53]

Episode 4 offers strategies for mitigating the risk of mining open-source social media content that may or may not be publicly available. [6:43]

Episode 5 offers strategies for mitigating the risk of unintentionally including hallucinations or fabricated data in research involving human subjects. [6:10]
Since 2023, the UK Center for Applied Artificial Intelligence has been at the forefront of AI, making investments in people and technology to empower others to explore AI and create meaningful solutions. Today, the Center is a specialized community who empowers faculty, staff, researchers, and clinicians to use AI to advance research, improve health outcomes, enhance student experiences, and drive productivity. Our team includes early and late-career software developers, project managers, data scientists, and advisors who guide our collaborators to overcome common AI barriers, such as technical expertise and access to secure compute resources. Without requiring a technical background or costly investments, we help our collaborators quickly turn ideas into prototypes and prototypes into solutions that make an impact for the communities they serve. Since our inception, we’ve supported more than 100 projects, have a network of 43 partners and over 120 individual collaborators. Please fill out our Collaboration Intake Form to connect.
Recommendations on the Use of Generative AI in Research and Scholarly Activity. UK ADVANCE offers guidance in response to frequently asked questions (FAQs) about the use of artificial intelligence from the UK research community.